QuaRot:基于旋转的离群值抑制算法说明¶
简介¶
- 来源:学术研究/业界 proposed 方法。
- 概述:QuaRot (Quantization with Rotation) 是一种用于大语言模型量化的创新算法,通过数学变换有效抑制激活张量中的离群值。该算法通过对权重和激活值进行特定的旋转变换,将离群值“分散”到多个通道中,从而在量化前显著平滑数据的分布,有效降低量化误差。
- 核心思想:QuaRot 的核心思想是应用一个精心构造的正交变换(旋转矩阵),使得变换后的激活张量在每个通道上的最大值尽可能均衡,从而避免单个通道因存在极端离群值而需要过大的缩放因子,进而提升整体量化精度。
使用前准备¶
安装 msModelSlim 工具,详情请参见《msModelSlim工具安装指南》。
原理和实现¶
原理¶
- 核心概念: QuaRot 采用正交旋转矩阵**(如 Hadamard 矩阵)对模型权重和激活值进行变换。正交矩阵满足 Q × Qᵀ = I 的关键性质,确保变换前后模型数学等价。
- 旋转变换操作:
对权重矩阵 W 应用变换:
W' = Qᵀ × W。 对激活值 X 应用变换:X' = X × Q。 变换保持计算等价:X' × W' = (X × Q) × (Qᵀ × W) = X × W。 - 计算不变性:
旋转变换保持 Transformer 各层的输入-输出映射关系不变。即使层间包含 RMSNorm 操作,因
RMSNorm(X) = RMSNorm(X × Qᵀ) × Q,计算不变性依然成立。 - 优化效果: 通过旋转重新分布参数,有效抑制激活值中的离群值,使数值分布更平滑,显著降低后续量化操作的误差,为低比特量化奠定基础。
实现¶
代码实现¶
算法在 msmodelslim/processor/quarot/offline_quarot/quarot.py 中实现。
处理流程时序图¶
以下时序图展示了QuaRot算法的完整处理流程,包括Runner、QuaRotProcessor、ModelAdapter和LAOSOnlineRotationProcessor之间的交互:
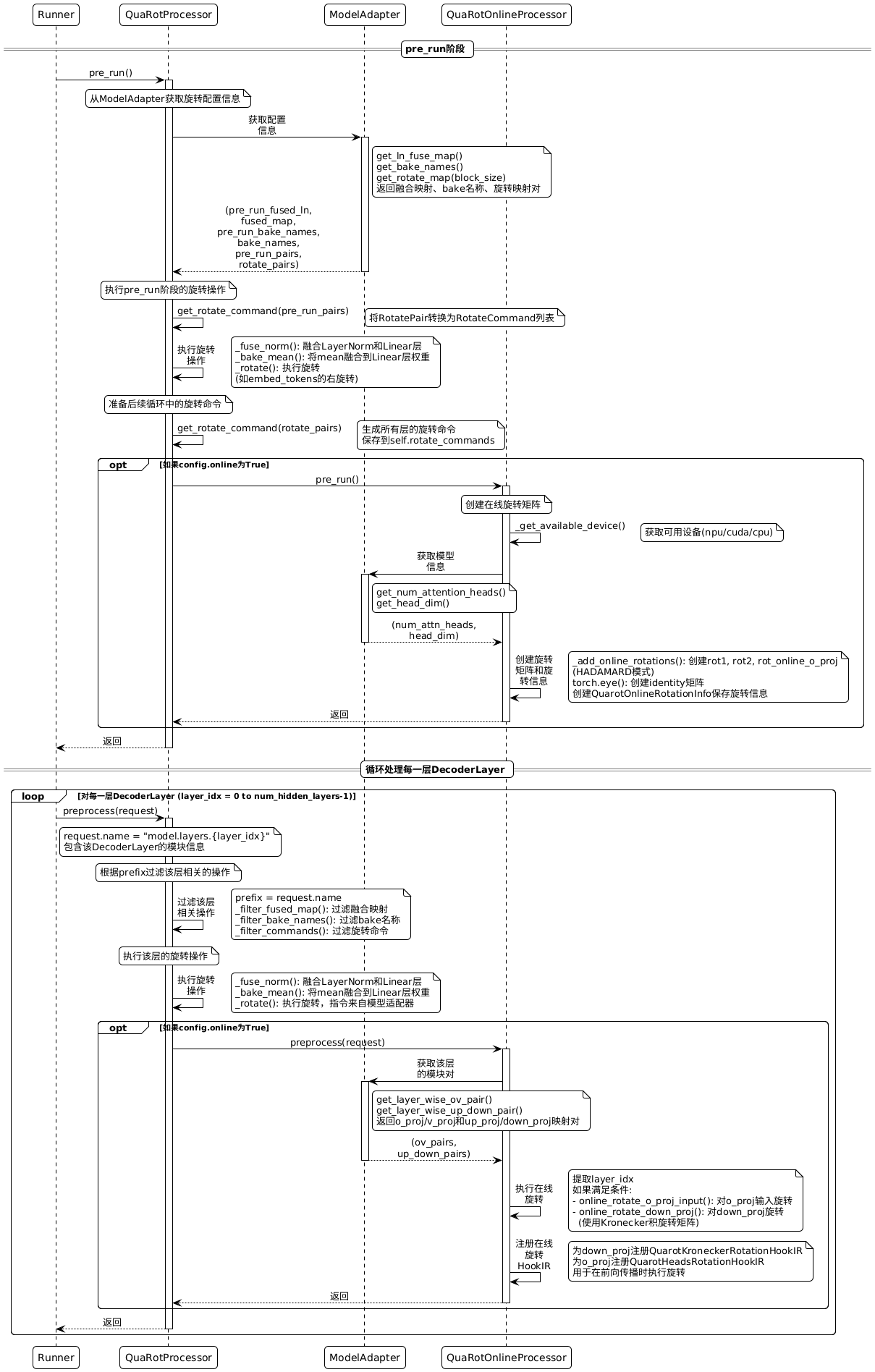
pre_run阶段¶
pre_run阶段在Runner开始逐层调度前执行,主要完成以下操作:
从模型适配器获取配置信息:
- 调用
adapter.get_ln_fuse_map()获取LayerNorm与Linear层的融合映射,返回(pre_run_fused_ln, fused_map),其中pre_run_fused_ln用于pre_run阶段,fused_map保存用于后续preprocess阶段。 - 调用
adapter.get_bake_names()获取需要mean融合的Linear层名称列表,返回(pre_run_bake_names, bake_names)。 - 调用
adapter.get_rotate_map(block_size)获取旋转映射对,返回(pre_run_pairs, rotate_pairs),其中pre_run_pairs用于pre_run阶段(通常包含embedding层的旋转),rotate_pairs保存用于后续preprocess阶段。
执行pre_run阶段的旋转操作:
- 将
pre_run_pairs转换为RotateCommand列表。 - 执行
_fuse_norm(pre_run_fused_ln):融合LayerNorm和Linear层,将LayerNorm的权重融合到Linear层,并将LayerNorm权重置为1。 - 执行
_bake_mean(pre_run_bake_names):将mean融合到Linear层权重中(通常为空列表)。 - 执行
_rotate(pre_run_commands):对指定层(如model.embed_tokens)执行旋转操作。
准备后续循环中的旋转命令:
- 将
rotate_pairs转换为RotateCommand列表并保存到self.rotate_commands,供preprocess阶段使用。
导出全局旋转信息(可选):
- 若配置项
export_extra_info为 True,则向首个旋转目标模块注册QuaRotExtraInfoHookIR,在保存阶段额外导出 QuaRot 全局旋转矩阵信息。 - 导出后在量化保存目录中会新增:
optional/quarot.safetensors:包含 key 为global_rotation的 tensor,该 tensor 即 QuaRot 使用的全局旋转矩阵Q。quant_model_description.json中新增optional.quarot域:用于描述上述额外导出件,便于推理侧按描述加载。optional.quarot的结构如下:
{
"optional": { // 可选导出件总入口
"quarot": { // QuaRot 额外导出域
"rotation_map": { // 旋转信息映射表
"global_rotation": "optional/quarot.safetensors" // 全局旋转矩阵文件(相对路径)
}
}
}
}
- 若
export_extra_info为 False,则不注入该 Hook,也不会导出上述信息。
在线旋转初始化(可选):
- 如果配置中
online: True,调用online_processor.pre_run():- 获取可用设备(npu/cuda/cpu)。
- 从适配器获取
num_attn_heads和head_dim。 - 创建在线旋转矩阵(rot1, rot2, rot_online_o_proj)和identity矩阵。
- 创建
QuarotOnlineRotationInfo对象保存旋转信息。
preprocess阶段¶
preprocess阶段在Runner调度每个DecoderLayer时执行,逐层处理每个decoder层。
根据prefix过滤该层相关的操作:
- 从
request.name提取prefix(如"model.layers.0")。 - 调用
_filter_fused_map(prefix):从self.fused_map中过滤出该层相关的LayerNorm融合映射,并从self.fused_map中移除。 - 调用
_filter_bake_names(prefix):从self.bake_names中过滤出该层相关的bake名称,并从self.bake_names中移除。 - 调用
_filter_commands(prefix):从self.rotate_commands中过滤出该层相关的旋转命令,并从self.rotate_commands中移除。
执行该层的旋转操作:
- 执行
_fuse_norm(fused_map):融合该层的LayerNorm和Linear层(如input_layernorm与q_a_proj的融合)。 - 执行
_bake_mean(bake_names):将该层的mean融合到Linear层权重中。 - 执行
_rotate(rotate_commands):执行该层的旋转操作,旋转操作的具体内容来自模型适配器。
在线旋转操作(可选):
- 如果配置中
online: True,调用online_processor.preprocess(request):- 从适配器获取该层的
ov_pairs(o_proj和v_proj的映射对)和up_down_pairs(up_proj和down_proj的映射对)。 - 提取
layer_idx。 - 如果满足条件,执行
online_rotate_o_proj_input()对o_proj的输入进行在线旋转。 - 如果
layer_idx在down_proj_online_layers配置中,执行online_rotate_down_proj()对down_proj进行在线旋转(使用Kronecker积旋转矩阵)。 - 为down_proj注册
QuarotKroneckerRotationHookIR,为o_proj注册QuarotHeadsRotationHookIR,这些HookIR在前向传播时执行旋转操作。
- 从适配器获取该层的
post_run阶段¶
post_run阶段在Runner结束调度后执行,主要完成以下操作:
- 执行剩余的融合、bake和旋转操作(处理
self.fused_map、self.bake_names和self.rotate_commands中剩余的内容)。 - 清理状态,清空所有保存的映射和命令列表。
- 如果启用了在线旋转,调用
online_processor.post_run(),将HookIR转换为WrapperIR。
适用要求¶
- 模型结构限制:当前的适配器已支持Qwen3 Dense模型系列、Qwen3 MOE模型系列、DeepSeek-V3/R1系列。
- 张量并行限制:若在配置中启用了在线旋转,在使用推理引擎以TP并行的方式进行部署时,需要保证
tp_size为2的幂,并且tp_size需要小于等于QuaRot的配置参数max_tp_size,否则必然导致精度异常。 - 在线旋转限制:使用在线旋转通常可以获得更好的精度,但需要在部署时插入在线旋转的算子,这依赖于推理框架的支持,也会一定程度降低性能,在推理引擎都支持的背景下,用户需要自行权衡精度与性能。
功能介绍¶
昇腾AI处理器支持情况¶
| 产品系列 | 支持 |
|---|---|
| Atlas A3 训练系列产品/Atlas A3 推理系列产品 | ✓ |
| Atlas A2 训练系列产品/Atlas 800I A2 推理产品 | ✓ |
| Atlas 推理系列产品 | ✗ |
模型支持¶
QuaRot算法目前支持以下模型系列:
| 模型系列 | 具体模型 | 基础旋转 | 在线旋转 | 备注 |
|---|---|---|---|---|
| Qwen3 Dense系列 | Qwen3-8B Qwen3-14B Qwen3-32B |
✓ | ✓ | 支持完整的QuaRot功能,包括基础旋转和在线旋转 |
| Qwen3 MOE系列 | Qwen3-30B Qwen3-235B |
✓ | ✗ | 支持基础旋转功能 |
| DeepSeek-V3/R1系列 | DeepSeek-V3 DeepSeek-V3-0324 DeepSeek-R1 DeepSeek-R1-0528 DeepSeek-V3.1 DeepSeek-V3.2-Exp |
✓ | ✗ | 支持基础旋转功能 |
| Qwen3-VL系列 | Qwen3-VL-32B | ✓ | ✗ | 支持基础旋转功能 |
| Qwen3-VL-MoE系列 | Qwen3-VL-235B-A22B Qwen3-VL-30B-A3B |
✓ | ✗ | 支持基础旋转功能 |
说明:
- 基础旋转:所有支持的模型都实现了
QuaRotInterface接口,支持基础旋转功能。 - 在线旋转:目前仅Qwen3 Dense系列模型实现了
LAOSOnlineRotationInterface接口,支持在线旋转功能。如需使用在线旋转,请配置online: True。 - 对于未实现在线旋转接口的模型,配置
online: True会导致错误。
YAML配置示例¶
作为Processor使用,YAML配置示例如下:
spec:
process:
- type: "quarot" # 固定为 `quarot`,用于指定 Processor 类型。
online: False # 控制是否启用在线旋转,默认为 False。
block_size: -1 # 旋转矩阵启用块对角矩阵时每个块的大小, 取值范围为-1或2的幂次方,如果大于0必须为2的幂,若为-1,表示不进行块对角矩阵处理
max_tp_size: 4 # 最大张量并行大小,默认为4,仅在启用在线旋转时生效,必须大于0且为2的幂,拉起模型时设置的tp值必须<=max_tp_size
down_proj_online_layers: [ ] # 用于指定哪些层的down_proj使用在线旋转,默认为空
export_extra_info: True # 是否导出全局旋转矩阵:使用 ascend_v1_saver 时在量化权重路径下生成 optional 目录及 quant_model_description.json 追加字段,默认为 True
YAML配置字段详解¶
| 字段名 | 作用 | 类型 | 说明 | 默认值 |
|---|---|---|---|---|
| type | 处理器类型标识 | string |
固定值,用于标识这是一个QuaRot量化处理器 | "quarot" |
| online | 在线旋转开关 | bool |
是否启用在线旋转,True表示使用在线旋转,False表示不使用 | False |
| block_size | 旋转矩阵的对角块大小 | int |
旋转矩阵的对角块大小,取值范围为-1或大于0的2的幂,若为-1表示不进行块对角矩阵处理 | -1 |
| max_tp_size | 最大张量并行大小 | int |
该配置项仅在启用在线旋转时生效,最大张量并行大小,必须大于0且为2的幂或等于1 | 4 |
| down_proj_online_layers | 指定使用在线旋转的down层 | array[int] |
用于指定哪些层的down_proj使用在线旋转,类型为由层索引组成的列表 | [] |
| export_extra_info | 是否导出全局旋转信息 | bool |
为 True 时注入相应 HookIR;若使用 ascend_v1_saver,会在量化权重路径下生成 optional 目录保存额外 safetensors(含 QuaRot 全局旋转矩阵),并在 quant_model_description.json 中追加描述字段;为 False 则不导出 | True |
模型适配¶
接口与数据结构¶
该接口组用于使能模型自主适配QuaRot算法。QuaRot算法包含两个模型适配接口:QuaRotInterface(基础旋转接口)和
LAOSOnlineRotationInterface(在线旋转接口)。如果只需要基础旋转功能,只需实现QuaRotInterface;如果需要在线旋转功能,需要同时实现两个接口。
数据结构¶
class QuaRotMode(Enum):
HADAMARD = "hadamard"
BLOCK_HADAMARD = "block_hadamard"
BLOCK_HADAMARD_SHIFTED = "block_hadamard_shifted"
class RotSide(Enum):
"""旋转方向枚举"""
LEFT = "left" # 左旋转
RIGHT = "right" # 右旋转
@dataclass
class RotateCommand:
"""旋转命令数据类"""
target: str # 目标模块名称
rot: Any # 旋转矩阵
side: RotSide # 旋转方向
@dataclass
class RotatePair:
"""旋转对数据类,包含左旋转和右旋转的映射"""
left_rot: Dict[str, Any] # 左旋转映射:{模块名: 旋转矩阵}
right_rot: Dict[str, Any] # 右旋转映射:{模块名: 旋转矩阵}
QuaRotInterface(基础旋转接口)¶
class QuaRotInterface:
"""QuaRot基础旋转接口,用于模型适配基础旋转功能"""
# 静态方法:创建旋转矩阵
@staticmethod
def get_rotate_command(mode: QuaRotMode,
size: int,
block_size: int = -1,
rot_step: int = 1,
eye_step: tuple = (-1,)) -> torch.Tensor:
"""
创建旋转矩阵
Args:
mode: 旋转模式(如HADAMARD、BLOCK_HADAMARD等)
size: 矩阵大小
block_size: 块大小,-1表示不使用块对角矩阵
rot_step: 旋转步长
eye_step: 单位矩阵步长
Returns:
旋转矩阵
"""
...
@abstractmethod
def get_ln_fuse_map(self) -> Tuple[Dict[str, List[str]], Dict[str, List[str]]]:
"""
获取LayerNorm与Linear层的融合映射
Returns:
包含两个字典的元组:
- pre_run_fused_ln (Dict[str, List[str]]): pre_run阶段的融合映射
- fused_map (Dict[str, List[str]]): preprocess阶段的融合映射
字典的key为LayerNorm层名称,value为需要融合的Linear层名称列表
"""
...
@abstractmethod
def get_bake_names(self) -> Tuple[List[str], List[str]]:
"""
获取需要mean融合的Linear层名称列表
当模型使用nn.LayerNorm时,需要在LayerNorm之前的Linear层进行mean融合。
通常不需要配置。
Returns:
包含两个列表的元组:
- pre_run_bake_names (List[str]): pre_run阶段的bake名称列表
- bake_names (List[str]): preprocess阶段的bake名称列表
"""
...
@abstractmethod
def get_rotate_map(self, block_size: int) -> Tuple[List[RotatePair], List[RotatePair]]:
"""
获取旋转映射,包括左旋转和右旋转的配置
Args:
block_size: 旋转的块大小
Returns:
包含两个RotatePair列表的元组:
- pre_run_pairs (List[RotatePair]): pre_run阶段的旋转映射对列表
通常用于embedding层的旋转
- rotate_pairs (List[RotatePair]): preprocess阶段的旋转映射对列表
通常用于对于decoderlayer层的旋转
"""
...
LAOSOnlineRotationInterface(在线旋转接口)¶
class LAOSOnlineRotationInterface:
"""QuaRot在线旋转接口,用于模型适配在线旋转功能"""
@abstractmethod
def get_head_dim(self) -> int:
"""
获取注意力头的维度
Returns:
注意力头的维度大小
"""
...
@abstractmethod
def get_num_attention_heads(self) -> int:
"""
获取注意力头的数量
Returns:
注意力头的数量
"""
...
@abstractmethod
def get_layer_wise_ov_pair(self, decoder_module: nn.Module) -> Dict[nn.Module, nn.Module]:
"""
获取单个decoder层对应的o_proj和v_proj映射对
Args:
decoder_module: decoder层的模块对象
Returns:
字典,key为o_proj模块,value为v_proj模块
"""
...
@abstractmethod
def get_layer_wise_up_down_pair(self, decoder_module: nn.Module) -> Dict[nn.Module, nn.Module]:
"""
获取单个decoder层对应的up_proj和down_proj映射对
Args:
decoder_module: decoder层的模块对象
Returns:
字典,key为up_proj模块,value为down_proj模块
"""
...
适配步骤¶
-
前置要求:
- 确保所有返回的模块引用都是实际模型中的模块对象。
- 模块路径必须与
model.named_modules()返回的路径完全一致。 - 返回的字典中的key和value必须是模块的完整路径字符串(如
"model.layers.0.self_attn.q_proj")。
-
步骤:
-
实现QuaRotInterface(必需):
- 模型适配器继承
QuaRotInterface接口,并实现所有抽象方法。 - 实现
get_ln_fuse_map():返回LayerNorm与Linear层的融合映射。 - 实现
get_bake_names():返回需要mean融合的Linear层名称列表(通常返回空列表)。 - 实现
get_rotate_map(block_size):返回旋转映射对,包括pre_run和preprocess阶段的旋转配置。 - 可参考 msmodelslim/model/qwen3/model_adapter.py 或 msmodelslim/model/deepseek_v3/model_adapter.py 的实现。
- 模型适配器继承
-
实现LAOSOnlineRotationInterface(可选,仅当需要在线旋转时):
- 如果配置中
online: True,需要同时实现LAOSOnlineRotationInterface接口。 - 实现
get_head_dim():返回注意力头的维度。 - 实现
get_num_attention_heads():返回注意力头的数量。 - 实现
get_layer_wise_ov_pair(decoder_module):返回o_proj和v_proj的映射对。 - 实现
get_layer_wise_up_down_pair(decoder_module):返回up_proj和down_proj的映射对。
- 如果配置中
-
FAQ¶
旋转矩阵创建失败¶
现象:输入模型的维度暂未被支持,导致旋转矩阵创建失败。
解决方案:请先确定指定维度的 Hadamard 矩阵存在,参考 msmodelslim/processor/quarot/common/hadamard_txt 添加特定维度的矩阵,并在 msmodelslim/processor/quarot/common/hadamard.py 进行补充。
张量并行配置错误¶
现象:在使用推理引擎以TP并行的方式进行部署时出现精度异常。
原因:tp_size不是2的幂,或者tp_size大于QuaRot配置的max_tp_size。
解决方案:
- 确保tp_size为2的幂(如1、2、4、8等)。
- 确保tp_size ≤ max_tp_size。
- 检查推理引擎是否支持在线旋转算子。
在线旋转性能问题¶
现象:启用在线旋转后推理性能下降明显。
原因:在线旋转需要插入额外的算子,会增加计算开销。
解决方案:
- 根据精度要求权衡是否启用在线旋转。
- 考虑仅使用离线旋转(
online: False)来平衡精度和性能。 - 确保推理框架对在线旋转算子有良好支持。
模型适配失败¶
现象:模型适配器无法正确识别模型结构,导致旋转操作插入失败。
原因:模型结构不兼容或适配器实现不完整。
解决方案:
- 确保模型基于Transformer decoder架构。
- 检查适配器是否正确实现了所有
QuaRotInterface接口方法(如果启用在线旋转,还需实现LAOSOnlineRotationInterface)。 - 参考 msmodelslim/model/qwen3/model_adapter.py 或 msmodelslim/model/deepseek_v3/model_adapter.py 的实现示例。